Concepts¶
Architecture¶
BrightstarDB is a native .NET NoSQL semantic web database. It can be used as an embedded database or run as a service. When run as a service clients can connect using HTTP, TCP/IP or Named Pipes. While the core data model is RDF triples and the query language SPARQL BrightstarDB provides a code-first Entity Framework. The Entity Framework tools take .NET interfaces and generate concrete classes that persist their data in BrightstarDB. As well as the Entity Framework there is a low level RDF API for working with the underlying data. BrightstarDB (in the Enterprise and Server versions) also provides a management studio called Polaris for running queries and transactions against a BrightstarDB service.
The following diagram provides an overview of the BrightstarDB architecture.
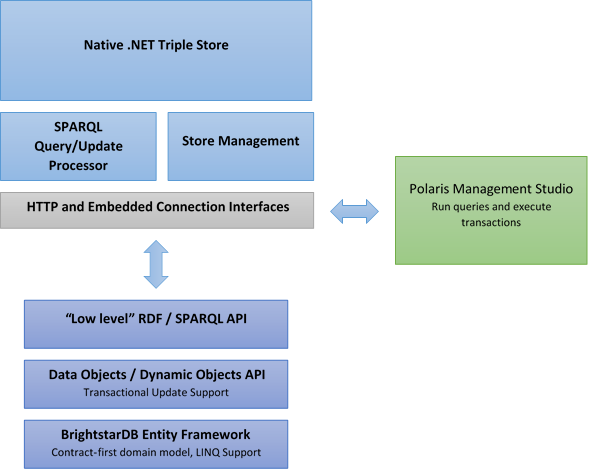
Data Model¶
BrightstarDB supports the W3C RDF and SPARQL 1.1 Query and Update. standards, the data model stored is triples with a graph context (often this is called a quad store). The triple data structure is very powerful, especially for creating associative data models, merging data from many sources, and for giving unique persistent and global identity to ‘things’.
A triple is defined as having three parts: A subject URI, a predicate URI, and an object value. The subject URI is the identifier for some thing. A person, company, product etc. The predicate is an identifier for a property type and the object can either be the identifier for another thing, or a literal value. Literal values can also have data types.
An example of a literal property assigned to some thing is:
<http://www.brightstardb.com/companies/brightstardb> <http://www.w3.org/2000/01/rdf-schema#label> "BrightstarDB" .
and a connection between two entities is described:
<http://www.brightstardb.com/companies/brightstardb> <http://www.brightstardb.com/types/hasproduct> <http://www.brightstardb.com/products/brightstardb> .
Storage Features¶
BrightstarDB is a write once, read many store (WORM). Modifications to data are appended to the end of the storage file, no data is ever overwritten. It employs a single writer, concurrent reader model. This supports concurrent read with no possibility of reading dirty data. Reads are not blocked while writes occur. The WORM store approach supports rollback or querying of the complete database at any transaction point. The store can be periodically coalesced to manage file size growth at the expense of removing previous transaction points.
Client APIs¶
There are three different code layers with which to access BrightstarDB. The first of these is the RDF Client API. This is a low level API that allows developers to insert and delete triples, and run SPARQL queries. The second API layer is the Data Object Layer. This provides the ability to treat a collection of triples with the same subject as a single unit and also provides support for RDF list structures and optimistic locking. The highest API layer is the BrightstarDB Entity Framework. BrightstarDB enables data-binding from items at the Data Object Layer to full .NET objects described by a programmer-defined interface. As well as storing object state BrightstarDB also allows developers to use LINQ expressions to query the data they have created.
Supported RDF Syntaxes¶
As BrightstarDB is built on the W3C RDF data model, we also provide the ability to import and export your data as RDF.
BrightstarDB supports a number of different RDF syntaxes for file-based import. This list of supported file formats applies both to import jobs created using the BrightstarDB API (see RDF Client API for details), and to file import using Polaris (see Polaris Management Tool for details). To determine the parser to be used, BrightstarDB checks the file extension, so it is important to use the correct file extension for the syntax you are importing. The supported syntaxes and their file extensions are listed in the table below as shown, BrightstarDB also supports reading from files that are compressed with the GZip compression method.
The table below also lists the MIME media types that are recognized by BrightstarDB for each of the supported RDF formats. Where more than one media type is listed, the first media type in the list is the preferred media type - this is the media type that BrightstarDB will use when emitting RDF in that particular format. We recommend that if you have a choice, you use the preferred media type - the other media types are supported for backwards compatibility and compatibility with media types used “in the wild”.
| RDF Syntax | File Extension (uncompressed) | File Extension (GZip compressed) | Supported MIME Media Types |
|---|---|---|---|
| NTriples | .nt | .nt.gz | text/ntriples
text/ntriples+turtle
application/rdf-triples
application/x-ntriples
|
| NQuads | .nq | .nq.gz | application/n-quads
text/x-nquads
|
| RDF/XML | .rdf | .rdf.gz | application/rdf+xml
application/xml
|
| Turtle | .ttl | .ttl.gz | text/turtle
application/x-turtle
application/turtle
|
| RDF/JSON | .rj or .json | .rj.gz or .json.gz | text/json
application/rdf+json
|
| Notation3 | .n3 | .n3.gz | text/n3
text/rdf+n3
|
| TriG | .trig | .trig.gz | application/trig
application/x-trig
|
| TriX | .xml | .xml.gz | application/trix |